
¿Alguna vez te has preguntado cómo se siente la búsqueda por voz en Google sin esfuerzo? La respuesta está en la tecnología de reconocimiento automático de voz (ASR), que traduce el lenguaje hablado en texto en tiempo real.
Mientras que las herramientas básicas de conversión de voz a texto simplemente transcriben palabras, los sistemas ASR avanzados aprovechan la inteligencia artificial y el aprendizaje automático para ofrecer mayor precisión, reconocer diversos acentos, filtrar el ruido de fondo y captar el significado contextual. Esto los hace indispensables para asistentes virtuales, robots de servicio al cliente y motores de búsqueda por voz.
En esta guía, explicaremos cómo funciona ASR, desacreditaremos mitos comunes, exploraremos usos en el mundo real, como la suite de edición de video de Filmora, y describiremos desafíos y oportunidades futuros.
En este artículo
- ¿Qué es un sistema de reconocimiento automático de voz y cómo funciona?
- Mitos comunes sobre los sistemas ASR versus hechos
- Cómo utilizar la tecnología de reconocimiento automático de voz
- Desafíos con aplicaciones ASR y progresiones futuras
Parte 1:¿Qué es un sistema de reconocimiento automático de voz y cómo funciona?

Reconocimiento automático de voz transforma palabras habladas en texto escrito mediante la aplicación de inteligencia artificial, aprendizaje automático y modelos lingüísticos para analizar e interpretar señales de audio. Impulsa asistentes de voz como Siri y Alexa, impulsa servicios de transcripción, admite análisis de centros de llamadas y respalda herramientas de traducción en tiempo real.
El proceso va más allá de simplemente escuchar. Así es como normalmente funciona un sistema ASR:
¿Cómo funcionan los sistemas ASR?
- La voz se captura a través de un micrófono o un archivo de audio cargado.
- El preprocesamiento limpia la señal, reduciendo el ruido y mejorando la claridad.
- El audio se segmenta en fotogramas cortos y se extraen características como el tono, el tono y el ritmo.
- Un modelo acústico, entrenado en vastos corpus de habla, asigna estas características a probabilidades de fonemas.
- Un modelo de lenguaje predice las secuencias de palabras más probables basándose en la gramática, frases comunes y sintaxis, resolviendo ambigüedades (por ejemplo, distinguiendo "reconocer el habla" de "destrozar una bonita playa").
- Un algoritmo de decodificación combina evidencia acústica y lingüística para generar la transcripción final, a menudo en milisegundos.
Los sistemas ASR de última generación emplean redes neuronales profundas que refinan continuamente las predicciones a medida que aprenden de las correcciones del usuario, aumentando constantemente la precisión.
Parte 2:Mitos comunes sobre los sistemas ASR versus hechos
A pesar de su adopción generalizada, persisten conceptos erróneos sobre las capacidades de ASR.

| Mitos | Hechos |
| Los sistemas ASR son 100% precisos | Incluso los modelos líderes, como Speech-to-Text de Google y Whisper de OpenAI, en ocasiones malinterpretan el habla debido al ruido de fondo o acentos atípicos. La posedición sigue siendo recomendable, especialmente para aplicaciones críticas. |
| Los sistemas ASR entienden el lenguaje como los humanos | ASR se basa en la coincidencia de patrones estadísticos en lugar de en la comprensión semántica. Asigna sonidos a palabras mediante modelos probabilísticos (HMM, redes neuronales profundas), pero carece de una verdadera comprensión del significado. |
Parte 3:Cómo utilizar la tecnología de reconocimiento automático de voz
Más allá de los comandos de voz, ASR está integrado en herramientas de la industria para optimizar los flujos de trabajo. A continuación se muestra un tutorial práctico sobre el uso de ASR en Filmora, una popular plataforma de edición de vídeo.
Software de edición de vídeo con ASR – Filmora
La función de detección de oradores impulsada por IA de Filmora identifica automáticamente distintas voces en un video, generando títulos o subtítulos precisos. Esto ahorra mucho tiempo a los editores y mejora la accesibilidad.

Usando el flujo de trabajo ASR móvil de Filmora:
- Abre Filmora en tu teléfono y comienza un nuevo proyecto. Importa el vídeo.
- Toca Texto → Subtítulos AI .
- Especifica el idioma hablado o deja que Filmora lo detecte automáticamente, luego haz clic en Agregar subtítulos . El sistema analizará los hablantes y generará subtítulos.
- Seleccione una plantilla de título mediante Plantilla y aplíquelo a los títulos deseados.
- Ajusta la ubicación de los subtítulos arrastrando y edita el estilo del texto usando la barra de herramientas.
- Para mejorarlo, haga clic en Editar discurso para corregir errores o clonar una voz, luego presione Actualizar voz .
En el escritorio, el proceso refleja la versión móvil pero utiliza la función Voz a Texto. característica:
- Inicia Filmora y crea un nuevo proyecto. Añade tu vídeo a la línea de tiempo.
- Haga clic derecho en el clip y seleccione Voz a texto .
- Elija Títulos como formato de salida y haga clic en Generar .
- El texto transcrito aparece como títulos editables en la línea de tiempo.
Parte 4:Desafíos con las aplicaciones ASR y progresiones futuras

Si bien la ASR ha transformado muchas tareas, persisten varios obstáculos:
- Acentos y dialectos :La pronunciación, la entonación y la jerga regional pueden dar lugar a malas interpretaciones.
- Calidad de audio :El ruido de fondo, los ecos y los sonidos superpuestos degradan la precisión de la transcripción.
- Homófonos :Las palabras que suenan idénticas pero difieren en significado (p. ej., “allí”, “su”, “ellos”) pueden confundir los sistemas sin señales contextuales.
Abordar estos desafíos implica desarrollar modelos acústicos más sólidos que abarquen un espectro más amplio de variaciones del habla e integrar el procesamiento del lenguaje natural para proporcionar desambiguación contextual.
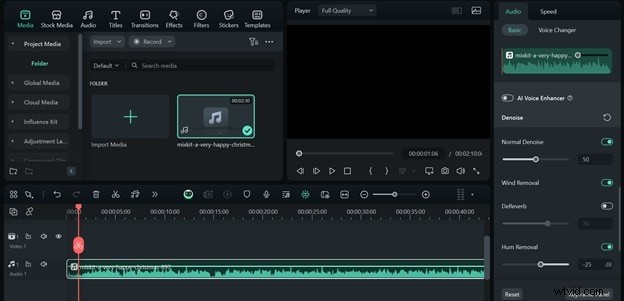
Mejora de la calidad del audio con Filmora
Para las herramientas ASR que aceptan cargas de audio, Filmora ofrece funciones de eliminación de ruido:
- Importa el clip de audio a la línea de tiempo.
- Seleccione el clip, abra el panel del editor y habilite la Normalización automática , Eliminar ruido , Eliminación del viento y Eliminación de zumbidos .
- Exporta el audio limpio como MP3 para obtener un rendimiento ASR óptimo.
Conclusión
Reconocimiento automático de voz está remodelando la forma en que interactuamos con la tecnología, desde simples transcripciones hasta sofisticadas soluciones industriales. Herramientas como Filmora ejemplifican cómo ASR puede automatizar los subtítulos y la limpieza de audio, aumentando la productividad y la accesibilidad.
A pesar de los obstáculos existentes, los avances continuos en IA y PNL prometen un reconocimiento de voz aún más preciso y versátil en un futuro próximo.

Filmora
⭐⭐⭐⭐⭐
El mejor software y aplicación de edición de vídeo con tecnología de IA