Estás editando un vídeo con varios oradores, tal vez un podcast o una entrevista. Agregar subtítulos manualmente es tedioso:hay que escuchar, escribir y sincronizar cada palabra hablada. ¿Qué pasaría si su editor de video pudiera reconocer automáticamente diferentes voces y generar subtítulos para cada orador? Ahí es donde el reconocimiento del hablante en Python cambia el juego.
Python es el lenguaje de programación preferido para desarrollar aplicaciones basadas en voz debido a sus sólidas bibliotecas. Estas bibliotecas le ayudan a implementar e implementar modelos de reconocimiento de hablantes para el procesamiento, análisis e identificación del habla en tiempo real. Por ejemplo, Pico Voice Eagle SDK ofrece una identificación rápida y precisa del hablante para aplicaciones basadas en IA.
Alternativamente, existen plataformas de edición de vídeo que integran inteligencia artificial de reconocimiento de voz. Funcionan escaneando el audio del vídeo, distinguiendo a los oradores y generando subtítulos sincronizados.
Esta guía explorará cómo implementar la identificación de hablantes en Python. También veremos las mejores alternativas sin código para subtitular vídeos sin esfuerzo.

En este artículo
- Fundamentos del procesamiento de audio
- Identificación de oradores en tiempo real con Picovoice Eagle SDK
- ¿Existen formas más sencillas de realizar el reconocimiento del hablante?
- ¿Dónde puedo utilizar aplicaciones de reconocimiento de oradores?
Parte 1:Fundamentos del procesamiento de audio

Todo sistema de reconocimiento de voz comienza con el procesamiento de audio. El sonido viaja como señales analógicas continuas, pero las computadoras requieren formatos digitales. Para convertir la voz en datos, utilizamos frecuencias de muestreo y técnicas de codificación de audio.
Una frecuencia de muestreo define la frecuencia con la que se graba el sonido por segundo. El estándar para el reconocimiento de locutores de Python es de 16 kHz, lo que garantiza una alta precisión. El formato del archivo de audio también importa:WAV, MP3 y FLAC son opciones comunes, aunque se prefiere WAV para tareas de aprendizaje automático.
Python simplifica la identificación de hablantes en tiempo real con bibliotecas especializadas como PyAudio y Picovoice Eagle SDK. Con estas herramientas, los desarrolladores pueden capturar, analizar y entrenar modelos para la identificación de hablantes en tiempo real en Python.
Parte 2:Identificación del hablante en tiempo real con Picovoice Eagle SDK
Picovoice Eagle SDK es una herramienta de alto rendimiento para reconocimiento de hablantes en Python . A diferencia de los modelos tradicionales, procesa el audio localmente. Este SDK es crucial para la identificación de hablantes en tiempo real en Python, especialmente en sistemas de seguridad de IA y asistentes inteligentes.
Además, es liviano y funciona a la perfección en múltiples plataformas, incluidas Windows, macOS, Linux, Android, iOS e incluso Raspberry Pi. Solo necesita registrarse en la consola Pico Voice y obtener su clave de acceso para autenticar su uso.
Instalación y configuración del SDK de Pico Voice Eagle en Python
Para integrar el SDK de Picovoice Eagle para el reconocimiento de hablantes en Python, instálelo primero. Antes de hacer esto, asegúrese de tener Python 3.6+ instalado.
Abra una terminal (Linux/macOS) o símbolo del sistema (Windows) y ejecute:
o
Si Python está instalado, mostrará algo como:
Si la versión es 3.6 o superior, estás listo para comenzar.
Para comenzar, instale las bibliotecas necesarias. Ejecute lo siguiente en su terminal:
pip install SpeechRecognition pyaudio librosa pvrecorder
Para Picovoice Eagle SDK, descargue e instale:
pip install pvporcupine pveagle
Guía paso a paso para implementar la identificación de hablantes en tiempo real utilizando Picovoice Eagle SDK en Python
- Paso 1:instalar Python. En el sitio web oficial de Python, seleccione la opción para descargar la versión más reciente, Python 3. x.x.
- Paso 2: A continuación, regístrese para obtener una cuenta gratuita de Picovoice Console y recupere su clave de acceso. Esta clave es necesaria para autenticar sus solicitudes cuando utiliza el SDK de Eagle Speaker Recognition.
- Paso 3: Instale los paquetes de Python necesarios. Ejecute el siguiente comando en su terminal:
pip instalar pveagle pvrecorder
Esto instalará PV Eagle (para reconocimiento de oradores) y PV Recorder (para captura de audio).
- Paso 4: Cree dos archivos en su VsCode. El primer archivo será para inscribir a un orador. La inscripción es el proceso de creación de un perfil de orador basado en datos de voz. Sigue estos pasos:
- Importar las bibliotecas necesarias
- Inicializa EagleProfile con tu clave de acceso
- Utilice PV Recorder para capturar muestras de voz
- Envíe fotogramas de audio a EagleProfile hasta que se complete la inscripción
- Exportar el perfil del orador para reconocimiento futuro
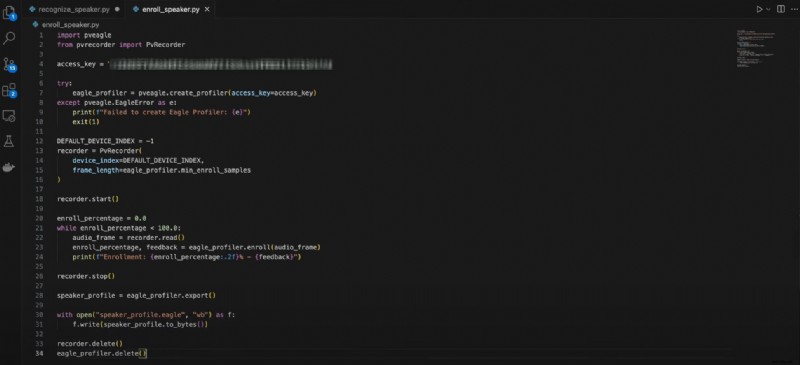
Aquí está el código para la inscripción de oradores:
importar pveagledesde pvrecorder importar PvRecorder
access_key ="TU_ACCESS_KEY"
prueba:
eagle_profiler =pveagle.create_profiler(clave_acceso=clave_acceso)
excepto pveagle.EagleError como e:
print(f"Error al crear Eagle Profiler:{e}")
salir(1)
DEFAULT_DEVICE_INDEX =-1
grabadora =PvRecorder(
índice_dispositivo=DEFAULT_DEVICE_INDEX,
frame_length=eagle_profiler.min_enroll_samples
)
grabadora.start()
porcentaje_inscripción =0,0
mientras que porcentaje_inscripción <100,0:
audio_frame =grabadora.leer()
porcentaje_inscripción, comentarios =eagle_profiler.enroll(marco_audio)
print(f"Inscripción:{enroll_percentage:.2f}% - {feedback}")
grabadora.stop()
perfil_altavoz =eagle_profiler.export()
con open("speaker_profile.eagle", "wb") como f:
f.write(speaker_profile.to_bytes())
grabadora.eliminar()
eagle_profiler.delete()
- Paso 5:Ve a tu terminal y graba ingresando el código a continuación
python3 enroll_speaker.py
Una vez que se esté ejecutando el script, intente hablar por el micrófono. Si su voz coincide con el perfil del hablante registrado, imprimirá "¡Altavoz reconocido!". De lo contrario, indicará un hablante desconocido.

- Paso 6: Ahora que el perfil del hablante está listo, creemos un código para el reconocimiento del hablante en tiempo real en el segundo archivo. Esto carga un perfil de orador y reconoce a un orador en tiempo real usando el SDK de Pico Voice Eagle.
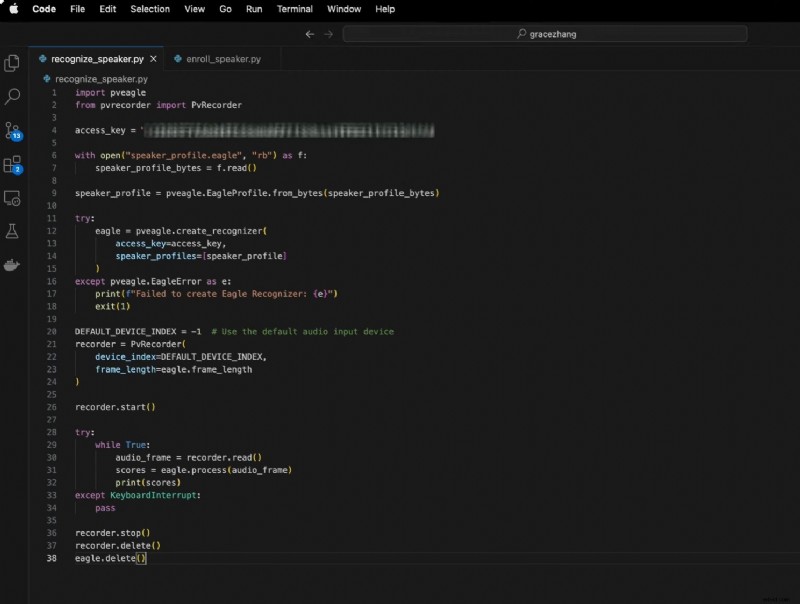
Esto implica:
- Crear una instancia Eagle con su clave de acceso y perfil de orador
- Usar PV Recorder para capturar audio en vivo
- Pasar los fotogramas de audio a Eagle para su reconocimiento en tiempo real
Aquí está el código:
importar pveagledesde pvrecorder importar PvRecorder
access_key ="TU_ACCESS_KEY"
con open("speaker_profile.eagle", "rb") como f:
altavoz_perfil_bytes =f.read()
perfil_altavoz =pveagle.EagleProfile.from_bytes(perfil_altavoz_bytes)
prueba:
águila =pveagle.create_recognizer(
clave_acceso=clave_acceso,
Speaker_profiles=[perfil_altavoz]
)
excepto pveagle.EagleError como e:
print(f"Error al crear Eagle Recognizer:{e}")
salir(1)
DEFAULT_DEVICE_INDEX =-1 # Usar el dispositivo de entrada de audio predeterminado
grabadora =PvRecorder(
índice_dispositivo=DEFAULT_DEVICE_INDEX,
frame_length=águila.frame_length
)
grabadora.start()
prueba:
mientras es Verdadero:
audio_frame =grabadora.leer()
puntuaciones =eagle.process(audio_frame)
imprimir (partituras)
excepto interrupción del teclado:
pasar
grabadora.parada()
grabadora.eliminar()
águila.delete()
- Paso 7:Pruebe y ejecute la aplicación.
Python3 recognize_speaker.py
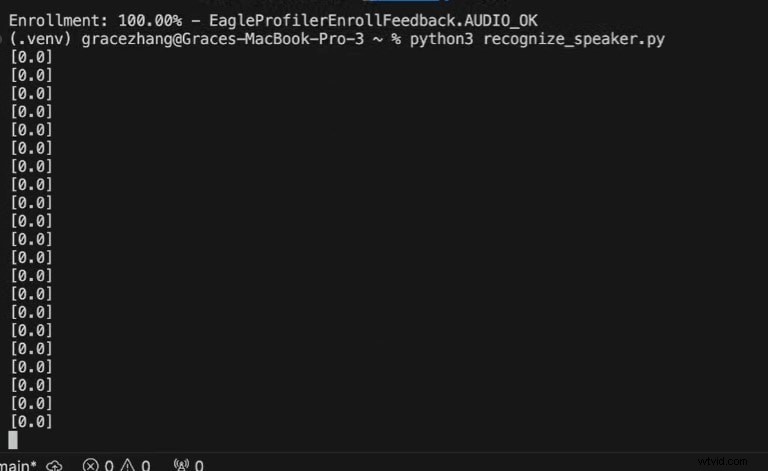
0 =Voz no reconocida
1 =Voz reconocida

Nota:A diferencia de los modelos basados en la nube, Picovoice Eagle SDK procesa datos localmente. Esto garantiza resultados más rápidos, mejor privacidad y sin dependencia de Internet.
La identificación de hablantes en Python solo puede ser comprendida y ejecutada por programadores profesionales. Es necesario tener cierto conocimiento de programación para comprender el proceso.
Parte 3:¿Existen formas más sencillas de realizar el reconocimiento del hablante?
Para crear un sistema de reconocimiento de hablantes en Python se necesitan habilidades de codificación y conocimientos técnicos. Si bien la identificación en Python es poderosa, puede resultar un desafío para los no programadores. Muchos usuarios prefieren herramientas listas para usar que ofrezcan funciones similares de reconocimiento de voz y hablantes. Es una mejor manera de realizar la tarea sin conocimientos de codificación.
Una de esas herramientas es WondershareFilmora, un editor de vídeo con reconocimiento de locutor y edición de voz integrados. Permite a los usuarios detectar, transcribir y modificar grabaciones de voz sin escribir una sola línea de código.
A diferencia del reconocimiento de hablantes de Python, que requiere entrenamiento manual del modelo, las herramientas integradas de Filmora automatizan el proceso. Puede editar y mejorar archivos de audio sin necesidad de conocimientos de Python o aprendizaje automático. Esto hace que la identificación del hablante sea accesible para los creadores de contenido, especialistas en marketing y usuarios comerciales.
Funciones de edición de voz y detección de altavoz móvil de Filmora
Filmora integra una herramienta impulsada por IA que simplifica la edición de audio y el reconocimiento de locutores. Con su versión móvil, los usuarios pueden acceder a funciones de detección de orador y edición de voz.
- Detección de altavoz. La detección de altavoz analiza el audio y distingue entre diferentes altavoces. En lugar de escuchar y etiquetar voces manualmente, la IA identifica quién está hablando y cuándo.
- Edición de voz. Editar un discurso puede ser tedioso, pero Speech Edit de Filmora simplifica el proceso. Permite a los usuarios cambiar las grabaciones de voz, ajustar la claridad y eliminar el ruido de fondo.
Cómo reconocer voz, convertir a texto y editar usando Filmora on the Go
Filmora simplifica el reconocimiento de hablantes con unos pocos clics. Aquí tienes una guía paso a paso:
- Paso 1:descarga Filmora, haz clic en “nuevo proyecto e importa el video con voz”.
- Paso 2:seleccione el texto para convertir las palabras habladas en texto.

- Paso 3:haz clic en los subtítulos de IA para iniciar el proceso de reconocimiento de voz
- Paso 4: haga clic en la opción Detección de orador antes de seleccionar Agregar subtítulos
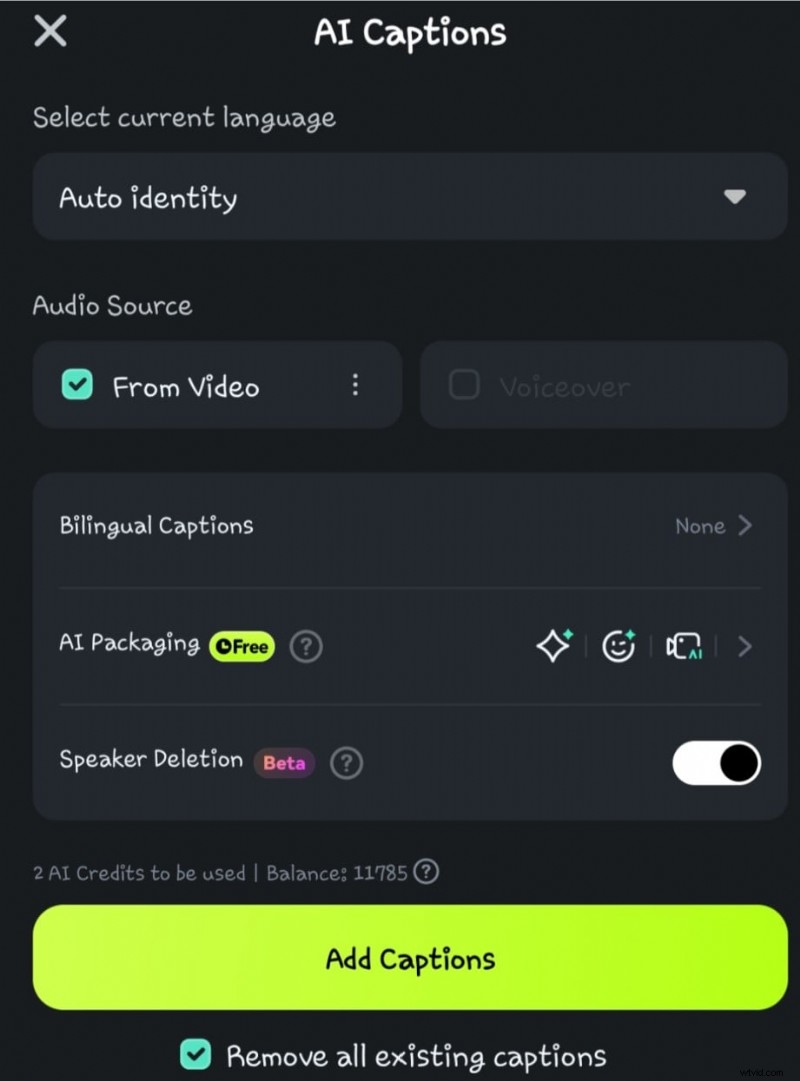
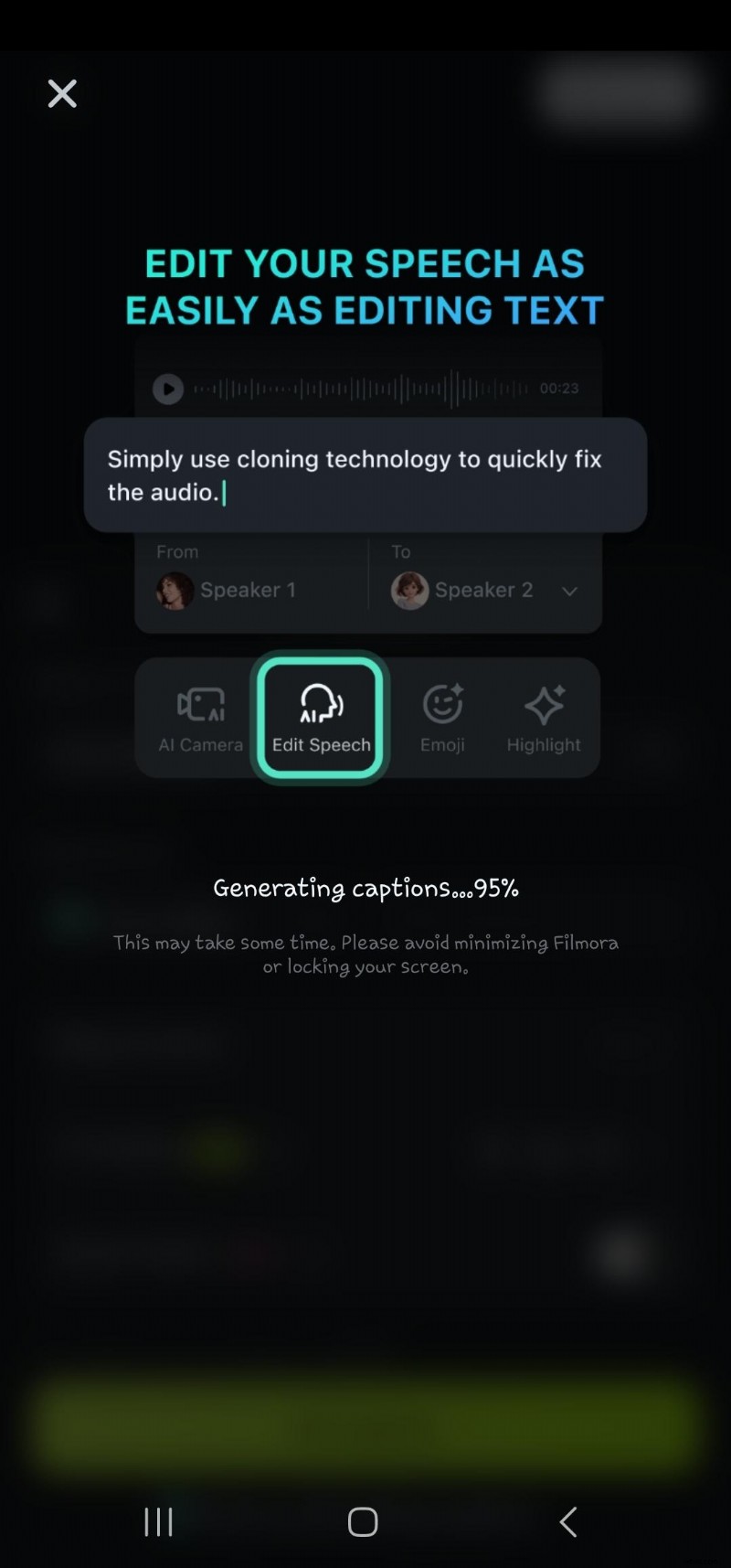
- Paso 5: Espera mientras la IA procesa la conversión de voz a texto
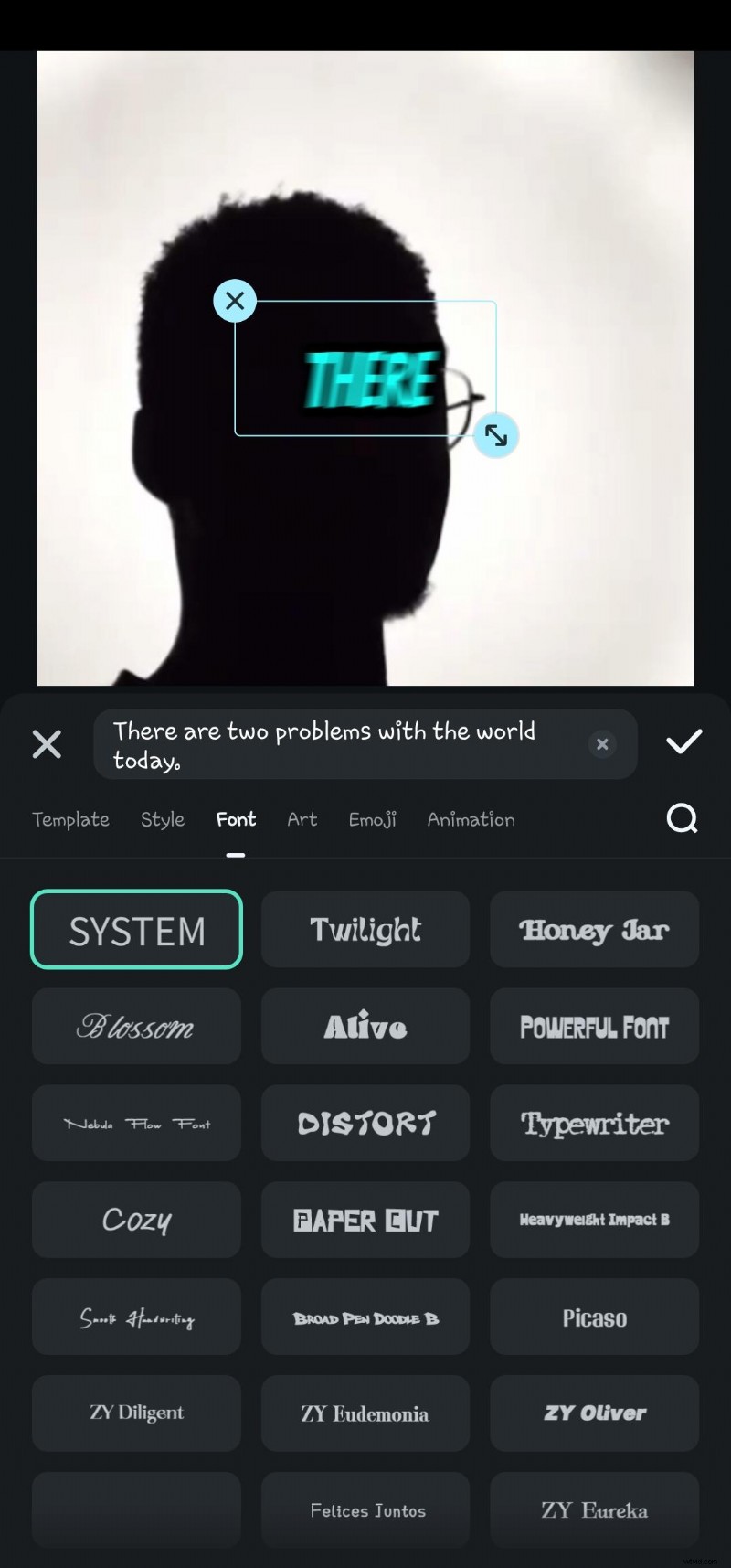
- Paso 6:haga doble clic en el texto generado en la línea de tiempo para navegar hasta la opción de edición de voz. Aquí puedes agregar animación, cambiar la plantilla del texto, la fuente, el estilo, el arte, etc.
- Paso 7:exporta el vídeo
Nota:Debes comprender que el reconocimiento de locutores de Python da control total sobre el entrenamiento del modelo. Pero Filmora ofrece un enfoque automatizado. Su función de IA garantiza un reconocimiento eficiente del hablante sin las complejidades de la programación.
Parte 4:¿Dónde puedo utilizar aplicaciones de reconocimiento de oradores?

Sin duda, el reconocimiento de los oradores en Python está transformando diversas industrias. Esta tecnología proporciona una forma rápida y confiable de identificar voces en videos o archivos de audio. Se está convirtiendo en una parte fundamental de diferentes industrias. A continuación se detallan las áreas donde se aplican estas aplicaciones.
- Asistentes inteligentes y dispositivos controlados por voz. Aplicaciones como Siri, Alexa y Google Assistant utilizan la identificación del hablante para distinguir las voces. Esto permite respuestas personalizadas, acceso seguro y comandos de voz personalizados para diferentes usuarios.
- Seguridad y autenticación de voz. Muchas empresas utilizan la identificación del hablante para verificar a los usuarios y evitar fraudes. Elimina la dependencia de las contraseñas al tiempo que mejora la protección de los datos y la comodidad del usuario.
- Transcripción y notas de reuniones impulsadas por IA. El reconocimiento de hablantes ayuda a aplicaciones como Otter.ai a diferenciar a los hablantes. Esto aumenta la precisión de la transcripción, especialmente aquellas con varias notas de voz.
- Centros de llamadas y atención al cliente. Los centros de llamadas utilizan el reconocimiento de hablantes en Python para mejorar la autenticación y detección de clientes. Los sistemas impulsados por IA identifican a las personas que llaman por voz, lo que reduce la necesidad de verificación manual de identidad. Esto mejora la seguridad, la eficiencia y los tiempos de respuesta en la atención al cliente.
- Salud y accesibilidad. Los hospitales y las aplicaciones de atención médica utilizan la identificación del hablante para una autenticación segura del paciente. Las herramientas de inteligencia artificial basadas en voz ayudan a las personas con movilidad limitada a acceder a dispositivos sin interacción física. El reconocimiento de locutores de Python garantiza un acceso médico seguro y mejora la atención al paciente.
Conclusión
Python es uno de los lenguajes más populares para la identificación de hablantes y voces. Proporciona bibliotecas potentes como SpeechRecognition, PyAudio, Librosa y Pico Voice Eagle SDK.
Estas herramientas permiten una alta precisión y una identificación del hablante en Python en tiempo real. . Esto la convierte en la mejor opción para desarrolladores, investigadores de inteligencia artificial y aplicaciones de seguridad. Filmora ofrece una alternativa más sencilla para quienes no tienen conocimientos de programación. Proporciona conversión de voz a texto, edición de voz y reconocimiento de hablante sin necesidad de codificación Python.
Prueba las herramientas impulsadas por IA de Filmora para la edición y transcripción automática de voz. Hacen que el proceso sea rápido y amigable.

Filmora
⭐⭐⭐⭐⭐
El mejor software y aplicación de edición de vídeo con tecnología de IA