Convertir voz en texto nunca ha sido tan fácil gracias a los modelos de conversión de voz a texto de Hugging Face. Ya sea que esté transcribiendo entrevistas, generando subtítulos o desarrollando aplicaciones basadas en inteligencia artificial, Hugging Face proporciona reconocimiento de voz de última generación impulsado por modelos avanzados de aprendizaje automático. ¿La mejor parte? Es altamente personalizable, lo que le permite ajustar los modelos para obtener una mayor precisión y rendimiento según sus necesidades específicas.
En esta guía, le explicaremos cómo configurar y utilizar la API Hugging Face de voz a texto , explore sus opciones de personalización y analice casos de uso prácticos. Pero ¿qué pasa si necesitas una alternativa más sencilla? No se preocupe:también presentaremos una herramienta de conversión de voz a texto fácil de usar que hace el trabajo sin esfuerzo. Si eres desarrollador, creador de contenidos o profesional de negocios, esta guía te ayudará a encontrar la mejor solución de conversión de voz a texto para tu flujo de trabajo. Sigue leyendo.
En este artículo
- Cómo funciona la conversión de voz a texto con cara de abrazo
- Configuración de voz abrazada en texto
- Una alternativa más sencilla:conversión automática de voz a texto con Filmora
- Qué herramienta es la mejor
Parte 1:Cómo funciona la conversión de voz en texto con cara de abrazo
Hugging Face Speech-to-Text es una gran característica dentro de la biblioteca Hugging Face Transformers que le permite convertir palabras habladas en texto escrito utilizando modelos previamente entrenados. Utiliza tecnología avanzada de reconocimiento automático de voz (ASR) para transcribir el habla. Con arquitecturas basadas en transformadores como Wav2Vec2, el sistema procesa datos de audio y los convierte en texto. Y lo hace con gran precisión.
Una de las cosas que hace que Speech-to-Text in Hugging Face Lo que destaca es su integración de canales, que lo hace muy fácil para los desarrolladores. Con sólo unas pocas líneas de código puedes procesar archivos de audio y obtener transcripciones de texto. Además, cuenta con modelos previamente entrenados para múltiples idiomas y escenarios de habla, por lo que es adaptable a muchos casos de uso.
El proceso de conversión de voz a texto sigue una secuencia paso a paso para garantizar una transcripción precisa:
- Entrada de audio:usted proporciona un archivo de audio para procesar.
- Extracción de funciones:el sistema extrae funciones de voz y bancos de filtros log-mel. Esto ayuda a analizar patrones de sonido.
- Inferencia de modelo:un modelo transformador previamente entrenado procesa las características y genera tokens de texto que representan palabras habladas.
- Salida de texto:el modelo convierte estos tokens en una transcripción de texto.
Los modelos de voz a texto de Hugging Face, particularmente SeamlessM4T-v2, mejoran la eficiencia al implementar un marco de doble secuencia a secuencia (seq2seq). Cuenta con codificadores de voz y texto separados, así como un codificador de voz HiFi-GAN, que mejora la calidad de la voz generada. Se trata de una herramienta útil para el reconocimiento y la automatización del habla, con aplicaciones que incluyen asistentes virtuales, subtítulos en vivo, servicios de transcripción y búsqueda por voz.
Parte 2:Configurar la voz de cara abrazada en texto
A continuación se muestra una guía paso a paso sobre cómo configurarlo para utilizar la voz de abrazo en texto:
Paso 1:Crea una cuenta de cara de abrazo

Lo primero que necesitas es una cuenta en Hugging Face. Crear una cuenta le brinda acceso a modelos y API previamente entrenados. Si aún no tienes una cuenta;
- Ir al sitio web de Hugging Face
- Haga clic en Registrarse
- Ingresa tus datos y crea una cuenta
- Una vez que hayas iniciado sesión, ve a la configuración de tu perfil
- Busque tokens de acceso y cree un token nuevo (elija "Escribir" como nivel de permiso)
Este token te ayudará a conectarte a Hugging Face desde tu código.
Paso 2:instalar las bibliotecas necesarias
Lo siguiente que debe hacer es instalar todas las bibliotecas que necesitará. Para hacer esto, abra su terminal o símbolo del sistema y escriba:
pip instalar transformadores conjuntos de datos torchaudio librosa archivo de sonido
Transformers sirve para cargar modelos de Hugging Face, torchaudio ayuda a procesar datos de audio, mientras que librosa y soundfile ayudan a cargar y modificar archivos de audio.
Paso 3:cargar el modelo
Después de instalar todas las bibliotecas necesarias, lo siguiente que debe hacer es cargar el modelo de voz a texto. Puede utilizar Wav2Vec2, ya que es uno de los mejores modelos previamente entrenados para el reconocimiento de voz.
desde transformadores importe Wav2Vec2ForCTC, Wav2Vec2Processor
importar antorcha
# Cargar el modelo y procesador
nombre_modelo ="facebook/wav2vec2-large-960h"
procesador =Wav2Vec2Processor.from_pretrained(nombre_modelo)
modelo =Wav2Vec2ForCTC.from_pretrained(nombre_modelo)
Paso 4:Convertir audio a texto
Debes tener listo tu archivo de audio para que el modelo pueda entenderlo. Para lograr esto, necesita cargar el audio en su software. Luego, asegúrese de que esté en el formato correcto para que el modelo pueda procesarlo adecuadamente. Lo ejecutará a través del modelo para transformar el discurso en texto.
importar librosa
#Cargue un archivo de audio y conviértalo a 16kHz
def load_audio(ruta_archivo):
audio, sr =librosa.load(file_path, sr=16000)
devolver audio
archivo_audio ="ejemplo.wav"
entrada_audio =cargar_audio(archivo_audio)
Procesa la entrada de audio para que el modelo pueda leerla
valores_entrada =procesador(entrada_audio, tensores_retorno="pt", velocidad_muestreo=16000).valores_entrada

Nota:Para proyectos más grandes, Hugging Face ofrece un punto final API que le permite procesar voz de forma remota sin administrar el modelo en su propio dispositivo. Simplemente regístrese para obtener una cuenta de Hugging Face, obtenga una clave API y envíe archivos de audio mediante una simple solicitud de API.
Cómo personalizar los modelos de voz a texto
Si desea que su modelo de cara abrazada de voz a texto funcione mejor, debe ajustarlo. El modelo básico es bueno, pero es posible que no comprenda ciertos acentos, ruidos de fondo o palabras especiales. Entrenarlo con sus propios datos le ayuda a aprender y mejorar, haciéndolo mucho más preciso para sus necesidades. Así es como puedes ajustar el modelo:
- Ajuste con datos personalizados:entrene el modelo con sus propios conjuntos de datos de audio y transcripción para mejorar el reconocimiento de acentos específicos o términos de la industria.
- Ajustar la configuración de inferencia:modifique parámetros como la temperatura y la búsqueda del haz para mejorar la precisión.
- Agregar vocabulario personalizado:enséñele al modelo nuevas palabras y frases relevantes para su dominio.
La personalización hace que el modelo sea más preciso y confiable para sus necesidades específicas. Pero si prefiere una solución más sencilla, consulte la siguiente sección para conocer una alternativa sencilla a la conversión de voz a texto.
Parte 3:Una alternativa más fácil:conversión automática de voz a texto con Filmora
Hugging Face Speech-to-Text parece demasiado complicado y requiere habilidades técnicas como codificación. Pero existe una alternativa más sencilla:Wondershare Filmora es un método mucho más sencillo para convertir voz en texto. Filmora es un popular software de edición de video que tiene una herramienta de conversión de voz a texto que transcribe audio automáticamente con unos pocos clics.
- Filmora te simplifica todo. Por lo tanto, no necesitas conocimientos de programación ni configuraciones complejas.
- Puede transcribir voz en vídeo a texto con hasta un 99 % de precisión. Por lo tanto, los creadores de contenido, estudiantes e incluso profesionales de negocios pueden usarlo para generar texto a partir de audio de manera rápida y precisa.
- Admite más de 45 idiomas y funciona bien para subtítulos de vídeos, notas de voz y entrevistas.
- Está equipado con traducción automática de subtítulos para contenido multilingüe
- Puedes generar subtítulos animados personalizables para mejorar la participación
- Además, la función de voz a texto incorporada de Filmora procesa datos de audio muy rápido y ahorra tiempo al usuario. Su velocidad y capacidad para ahorrar tiempo es lo que la convierte en la mejor alternativa.
Parte 4:Cómo utilizar Filmora Speech-to-Text
Filmora hace que sea muy sencillo convertir voz en texto. No es necesario crear código ni configurar nada complicado.
Simplemente siga estas sencillas instrucciones para obtener su transcripción en poco tiempo utilizando la función de voz a texto del escritorio:
Paso 1:importa tu audio o vídeo
Abre Filmora y agrega tu archivo de audio o video. Puedes hacer esto simplemente arrastrándolo y soltándolo en la línea de tiempo. Esto te lo pone más fácil. Una vez que su archivo esté en su lugar, estará listo para continuar.
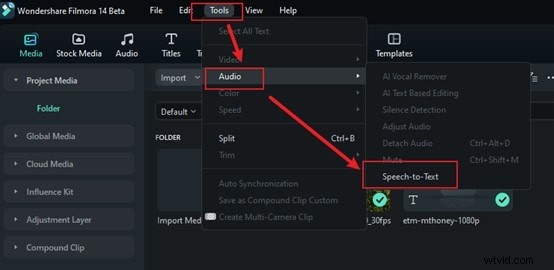
Paso 2:seleccione la opción de voz a texto
Vaya a Herramientas en la barra de menú superior y haga clic en ella. Elija la opción Audio y luego Texto a voz para analizar automáticamente su audio. No es necesario ajustar la configuración ni hacer nada adicional, ya que él se encarga de todo por usted.
Paso 3:elige tu idioma
Filmora admite muchos idiomas, así que elige el que coincida con tu audio. Este paso es importante porque elegir el idioma correcto ayuda a Filmora a transcribir tu discurso con precisión. Si omite esto, es posible que obtenga algunos resultados incorrectos.
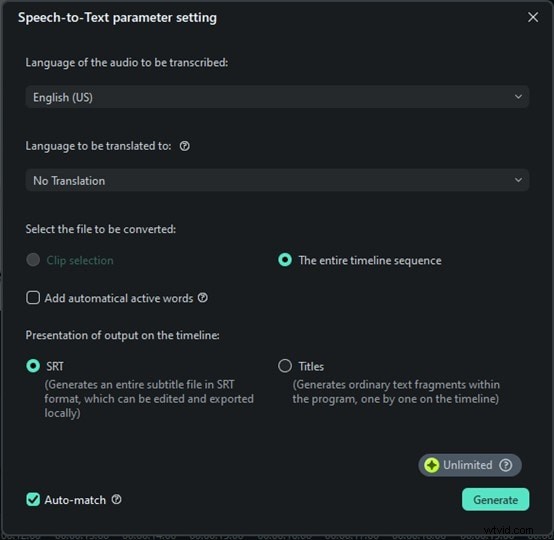
Paso 4:Inicia la transcripción y guarda
Ahora, simplemente haz clic en Generar y Filmora comenzará a transcribir tu discurso. Esta parte es realmente rápida. En unos segundos, verás que las palabras habladas aparecen como texto. Sin horas de espera, sin configuraciones complejas, solo resultados instantáneos. Haga clic en el archivo de texto, seleccione Exportar transcripción del archivo de subtítulos para guardarlo y agregarlo como subtítulos a su video.
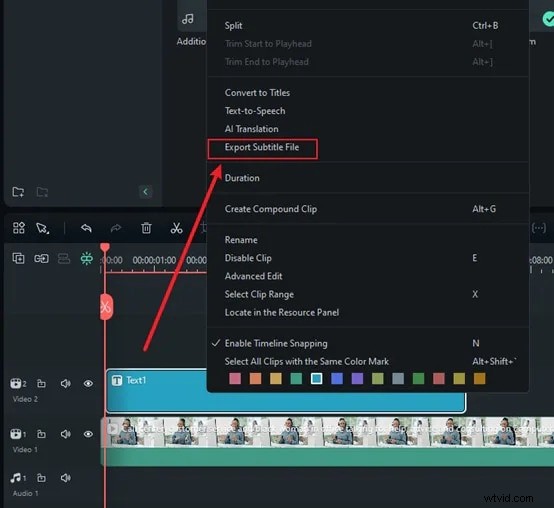
Si desea convertir voz de video en subtítulos de texto, Filmora también ofrece una función de subtítulos AI en su aplicación móvil. Te permite generar subtítulos de texto en tu dispositivo móvil en menos de un minuto
Paso 1:Descarga la aplicación Filmora desde Google Play Store (Android) o App Store (iPhone). También puedes conseguirlo desde el sitio web oficial. Una vez instalada, abre la aplicación y toca Nuevo proyecto.
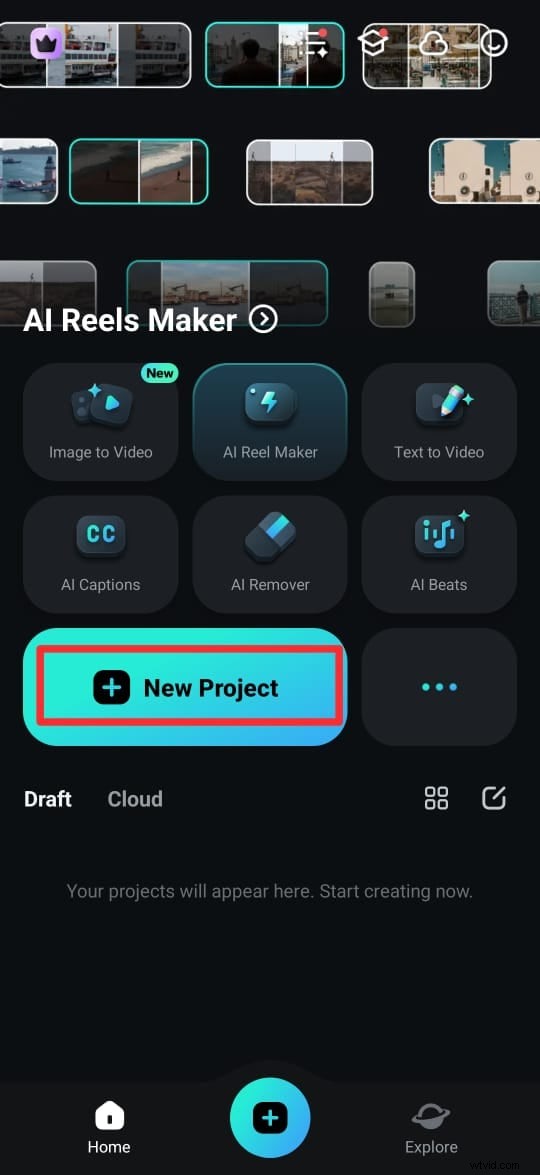
Paso 2. Elige un vídeo de tu biblioteca multimedia y toca Importar para agregarlo a tu espacio de trabajo.

Paso 3:en el menú inferior, toque Texto (marcado con un ícono T) y elija Subtítulos AI.
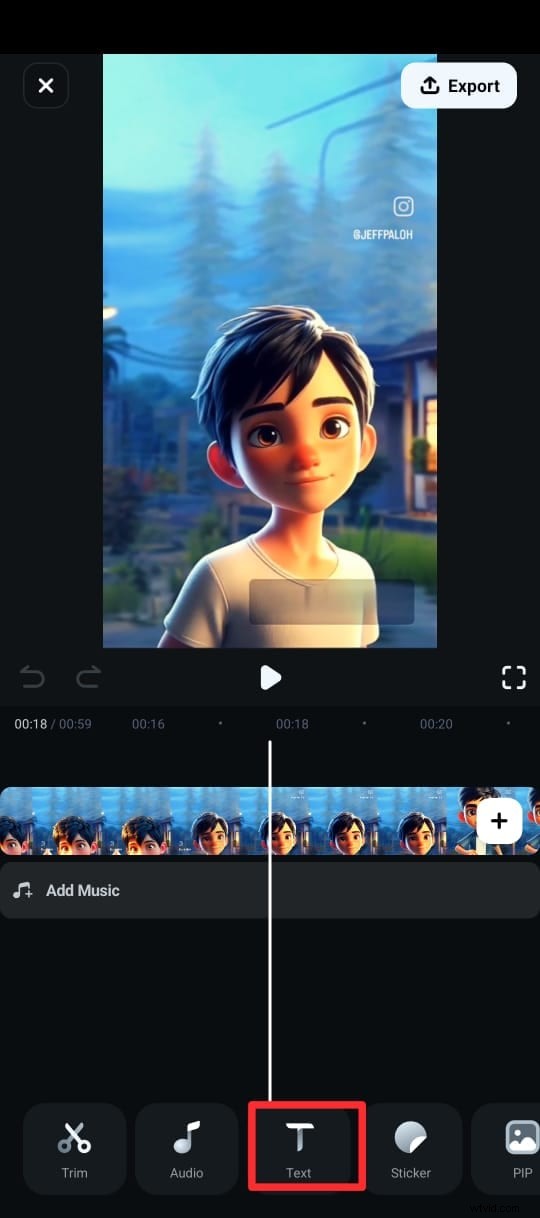
Paso 4:en la siguiente pantalla, seleccione el idioma, active Detección de orador y toque Agregar subtítulos para generar texto a partir del discurso del video.
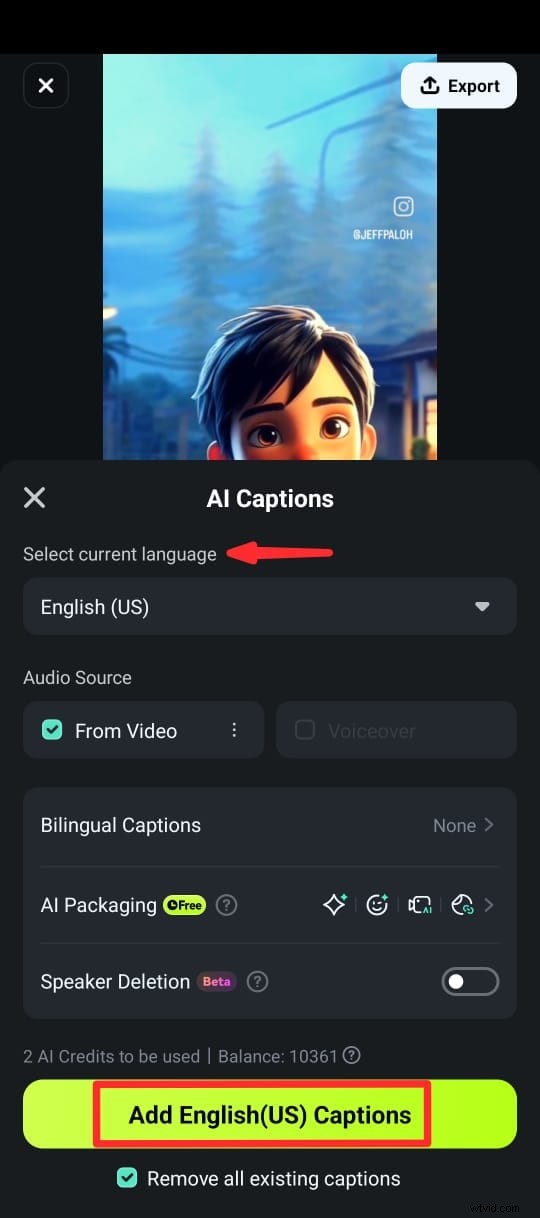
Paso 5:Una vez generados los subtítulos, puedes personalizar el texto usando diferentes plantillas de texto, emojis y fuentes. También puedes editar el texto del clip en la línea de tiempo seleccionando Editar voz en la suite de edición.
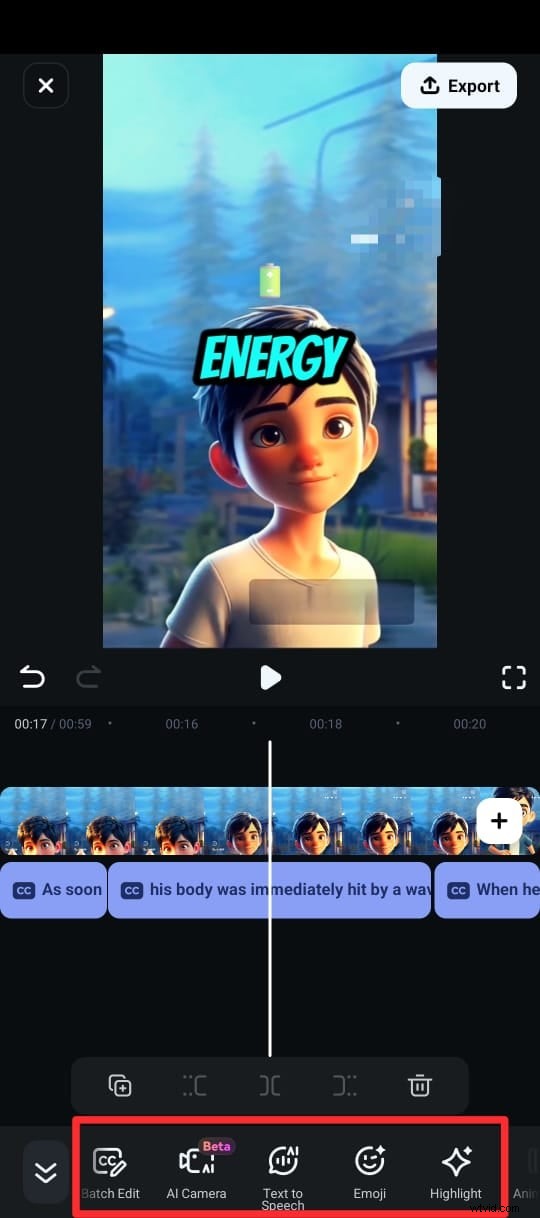
Paso 6:Exporta tu vídeo con subtítulos en el formato deseado.
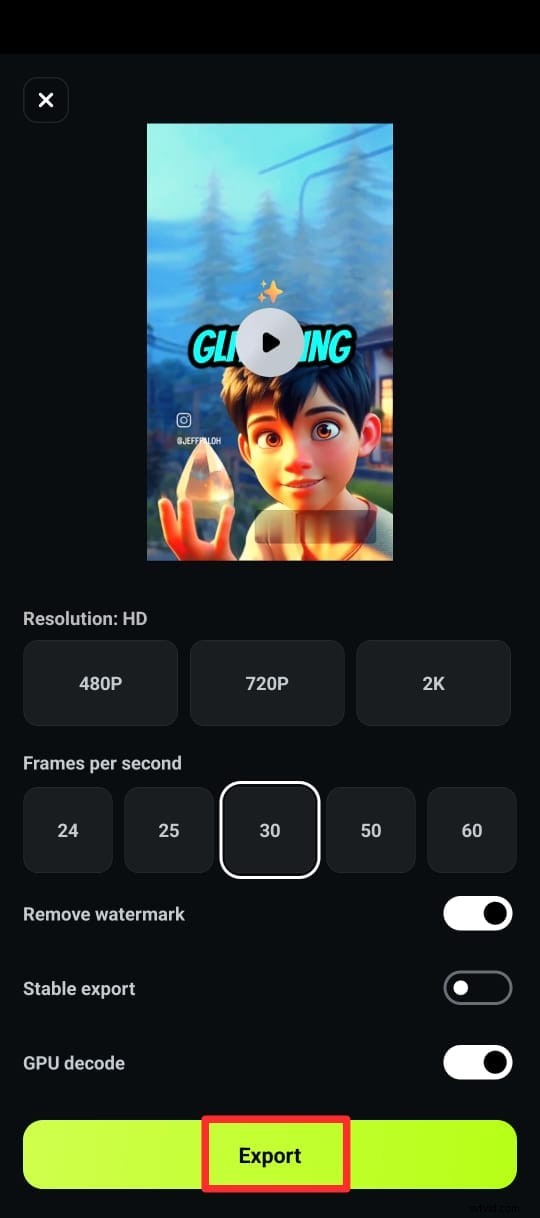
Parte 5. ¿Qué herramienta es la mejor?
Elegir entre Hugging Face y Filmora depende de tus necesidades específicas y de tu nivel de experiencia técnica. Cada herramienta tiene un propósito diferente, así que exploremos cuál es la adecuada para usted en función de diferentes escenarios.
- Si necesita personalización avanzada y control basado en IA, la conversión de voz a texto de Hugging Face es la mejor opción. Es ideal para desarrolladores, investigadores y profesionales que desean entrenar modelos, ajustar parámetros y trabajar con grandes conjuntos de datos. Sin embargo, requiere conocimientos de codificación y tiempo para configurarlo, lo que lo hace menos adecuado para principiantes o aquellos que buscan una solución rápida.
- Por otro lado, si deseas una herramienta de transcripción rápida y precisa sin ninguna configuración técnica, Filmora es el camino a seguir. Está diseñado para creadores de contenido, estudiantes y profesionales que necesitan una solución sencilla con un solo clic.
- Usa Filmora si estás agregando subtítulos a videos, transcribiendo conferencias o convirtiendo voz en texto para informes.
- Para aquellos que trabajan en campos específicos que requieren reconocimiento de voz de dominio específico, Hugging Face les permite entrenar el modelo en terminología específica de la industria. Esto garantiza una mayor precisión en la jerga compleja, pero, una vez más, requiere esfuerzo y conocimientos técnicos.
- Mientras tanto, si su objetivo principal es transcribir contenido de video, Filmora es una opción más conveniente, ya que convierte rápidamente voz en texto, lo que lo hace ideal para YouTubers, podcasters y creadores de redes sociales.
En resumen, si te encanta codificar y quieres control y personalización totales, opta por texto a voz en huggingface. Pero si quieres una herramienta de transcripción fácil e instantánea, Filmora es la elección perfecta. Elija el que mejor se adapte a su flujo de trabajo y nivel de habilidad.
Conclusión
Convertir voz en texto no tiene por qué ser complicado. Texto a voz de Hugging Face Es una herramienta poderosa pero requiere codificación y configuración, lo cual es genial para los desarrolladores. Sin embargo, si quieres algo rápido y fácil, Filmora es la mejor alternativa. Con sólo unos pocos clics, puedes transcribir audio sin esfuerzo; sin codificación, sin estrés. ¿Por qué dedicar horas a configuraciones complejas? Prueba hoy la función de conversión de voz a texto de Filmora y convierte tu audio en texto en segundos