GPT‑Image2 de OpenAI, lanzado el 21 de abril de 2026, es el modelo de imagen más nuevo de la compañía y el sucesor de DALL‑E. Introduce un cambio de paradigma:las imágenes ya no se generan mediante un proceso de difusión sino mediante un sistema autorregresivo que piensa, planifica y verifica antes de dibujar. El resultado es un modelo que ofrece imágenes realistas, texto multilingüe fluido y una capa de razonamiento integrada que lo distingue de cualquier otro generador de imágenes con IA del mercado.
Resumen rápido
- GPT‑Image2 es ahora el único modelo de imagen de OpenAI, tras el retiro de DALL‑E2 y 3 el 12 de mayo de 2026.
- Su arquitectura autorregresiva refleja la lógica de generación de texto utilizada en GPT‑4o, proporcionando una canalización consistente para píxeles y palabras.
- La precisión del texto ha aumentado al 99 % en inglés y a más del 90 % en chino, japonés, coreano, hindi, bengalí y árabe.
- El modelo puede planificar diseños, extraer datos de la web y autoverificar los resultados antes de finalizar la imagen.
- Las relaciones de aspecto varían de 3:1 a 1:3, con soporte nativo 16:9 y 9:16. La salida estándar es 2K; 4K está disponible en la API beta.
- Este artículo explica el cambio arquitectónico, las cinco características más impactantes, sus limitaciones, una comparación con Midjourney, FLUX y Nano Banana2, y cómo integrarlo en un flujo de trabajo más amplio con InVideo.
¿Qué es ChatGPT Images2.0?
GPT‑Image2 representa algo más que una salida más nítida; se comporta como un socio creativo. En lugar de traducir las indicaciones directamente a píxeles, el modelo interpreta la intención, planifica la composición y refina la imagen final. Está disponible dentro de ChatGPT y a través de la API OpenAI, posicionado como un generador de activos de nivel de producción para flujos de trabajo de diseño reales.
Cómo GPT‑Image2 puede transformar su flujo de trabajo creativo
1. Texto preciso en una sola pasada
Con una precisión del texto del 99 %, los títulos, subtítulos y CTA se representan correctamente en el primer intento, sin necesidad de realizar viajes de ida y vuelta con Photoshop ni realizar ediciones de diseñador. Una marca DTC puede generar diez variantes de anuncios, cada una con un texto único, y enviar los recursos finales directamente.

2. Maquetas de etiquetas y envases de productos
El texto de la marca en una etiqueta ya no es un punto débil. GPT‑Image2 deletrea con precisión los nombres y eslóganes de los productos en varios idiomas (mandarín, hindi, japonés, coreano y árabe) para que las marcas globales puedan lanzar imágenes que coincidan con su texto desde el primer día.

3. Activos sociales en todos los formatos
Las relaciones de aspecto ahora abarcan de 3:1 a 1:3, incluidos 16:9 y 9:16 nativos. Un solo mensaje puede producir una miniatura de YouTube, una historia de Instagram, un banner de LinkedIn y diapositivas en carrusel sin ningún recorte.

Miniatura de YouTube

Portada de Instagram

Diapositivas de carrusel
4. Infografía simplificada
Los diseños densos se mantienen coherentes. Múltiples puntos de datos, etiquetas y encabezados permanecen donde usted los coloca, lo que permite a las marcas B2B convertir informes con muchas estadísticas en infografías limpias y acordes con la marca sin tener que pasar a un diseñador.

5. Personajes, entornos e ilustraciones consistentes
Desde personajes de juegos hasta mascotas de marcas, GPT‑Image2 puede generar personalidades únicas, mundos de fantasía, ciudades futuristas y escenarios históricos, todo ello manteniendo la coherencia visual en todas las escenas.



Los escritores, creadores de cómics y editores pueden utilizar GPT‑Image2 para visualizar ritmos narrativos y experimentar con la narración visual.


6. Maquetas de UI y conceptos
Con un estricto seguimiento de instrucciones, GPT‑Image2 produce maquetas de interfaz de usuario limpias a partir de una simple descripción de pantalla. Los equipos de producto pueden entregar el resultado a los desarrolladores o partes interesadas para su aprobación.
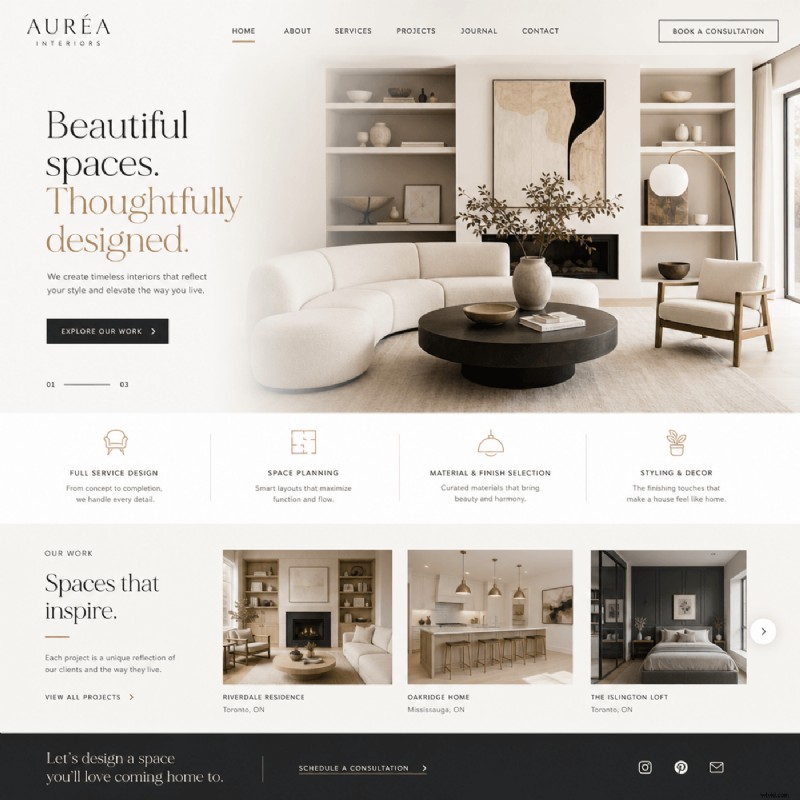
7. Portadas editoriales y diseños
Las portadas de revistas y los diseños de libros se benefician de una rápida exploración de conceptos. Las imágenes generadas por IA pueden dar vida a las historias de portada de maneras únicas, mientras que las ilustraciones editoriales mantienen un estilo visual consistente en todas las páginas.



Donde GPT‑Image2 aún se queda corto
- La transferencia de sesión puede introducir ruido; reinicie las sesiones entre lotes para obtener una calidad óptima.
- La generación repetida de carteles puede converger en un solo estilo; varíe las indicaciones con directivas de estilo explícitas para mantener la diversidad.
- La física, la precisión estructural, los datos técnicos, los rostros en primer plano y el texto en superficies curvas o empinadas siguen siendo un desafío. Trate los resultados como un punto de partida sólido que aún requiere revisión humana.

Las cinco funciones principales que distinguen a GPT‑Image2
1. Razonamiento incorporado
Antes de dibujar un píxel, el modelo analiza el mensaje, planifica la composición, obtiene datos externos y verifica su propia salida, reflejando la lógica de razonamiento de los modelos de texto de OpenAI.
2. 99 % de precisión en la representación de texto
GPT‑Image1.5 ofreció entre un 90% y un 95% de precisión; GPT‑Image2 reclama el 99 % de las escrituras latinas y CJK, lo que hace que los resultados de una sola pasada se puedan publicar sin necesidad de editarlos más.
3. Soporte multilingüe
Chino, japonés (kanji e hiragana), coreano, hindi, bengalí y árabe se representan con precisión, lo que abre mercados a los que los modelos anteriores no podían atender.
4. Alta resolución y relaciones de aspecto flexibles
La salida estándar es 2K (2048px). 4K está en API beta. Las relaciones de aspecto ahora incluyen 3:1 a 1:3, 16:9/9:16 nativo y cuadrado, lo que elimina la necesidad de recortar.
5. Fuerte seguimiento de instrucciones y control de la composición
Los comandos espaciales (“tres robots idénticos seguidos”), las indicaciones de edición múltiple y la manipulación de objetos por nombre funcionan de manera confiable, lo que permite que las composiciones densas, las infografías, los cómics y las páginas de revistas se mantengan coherentes.
GPT‑Image2 frente a Midjourney, Nano Banana2 y FLUX
| Modelo | Mejor para | Limitación |
|---|---|---|
| GPT‑Imagen2 | Imágenes con mucho texto, texto multilingüe, trabajo con diseño preciso, seguimiento de instrucciones, consistencia de múltiples imágenes | La física y el texto en 3D aún necesitan revisión humana; ecosistema más pequeño |
| Midjourneyv8 | Pura estética visual:trabajo editorial, cinematográfico y basado en el estilo | Sin API pública; texto no latino no confiable |
| Nano Plátano2 | Flujos de trabajo de gran volumen y económicos | Menos precisión en texto denso y diseños complejos |
| FLUX (Laboratorios de la Selva Negra) | Autohospedaje, ajuste fino y licencias de peso abierto | Ecosistema más pequeño, menos distribución |
Ejecutamos un único mensaje en los cuatro modelos y comparamos los resultados uno al lado del otro.
Prompt: "Create a premium YouTube thumbnail in a modern AI‑tech editorial style. Split the composition into two contrasting halves. On the left side, showcase stunning AI‑generated visuals emerging from a glowing ChatGPT‑inspired interface: cinematic portraits, realistic product photography, vibrant illustrations, and professional marketing creatives. Use bright lighting, vibrant colors, futuristic UI elements, and upward arrows to symbolize benefits and innovation. On the right side, depict the limitations and challenges of AI image generation: distorted hands, inconsistent text rendering, failed generations, quality issues, and warning symbols. Use darker tones, subtle glitch effects, red highlights, and broken image frames to create contrast. In the center, feature a large glowing AI image‑generation panel with an image transforming from rough concept to polished masterpiece. Add dynamic particles, depth, dramatic lighting, and premium tech aesthetics. Large bold headline text: Here’s EVERYTHING YOU NEED TO KNOW ABOUT CHATGPT IMAGES 2.0. Secondary text: BENEFITS vs FALLBACKS Typography should be huge, bold, modern sans‑serif, highly readable at mobile size. Use white text with subtle shadows and cyan accents. Maintain strong visual hierarchy similar to top‑performing AI and technology YouTube thumbnails. Ultra‑sharp, high contrast, professional, viral‑worthy, clean composition, 16:9 aspect ratio."
Accediendo a GPT‑Image2
En ChatGPT
La generación de imágenes base es gratuita para todos los usuarios. Al seleccionar un modelo Thinking o Pro se desbloquea la capa de razonamiento:búsqueda web en tiempo real durante la generación, hasta diez imágenes a la vez y continuidad de personajes/objetos entre ellas.
En vídeo (con retención de contexto)
Piloto automático
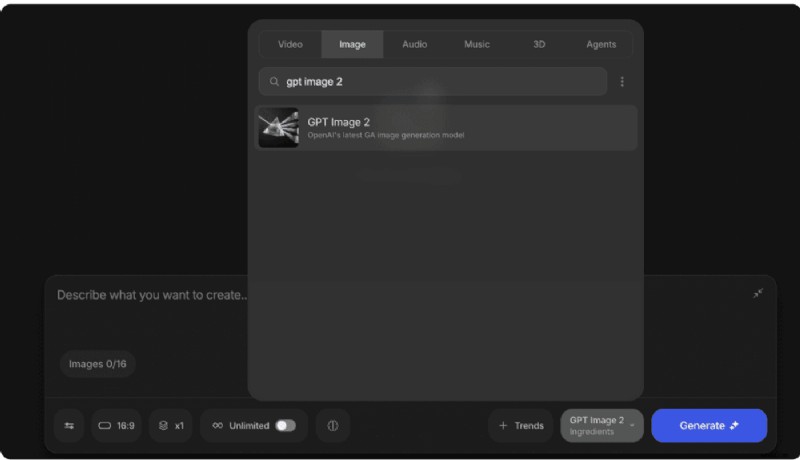
- Paso 1: Abra Agentes y modelos, elija GPT‑Image2.
- Paso 2: Escriba su mensaje, establezca la resolución y las variaciones, y genere.
AgenteUno
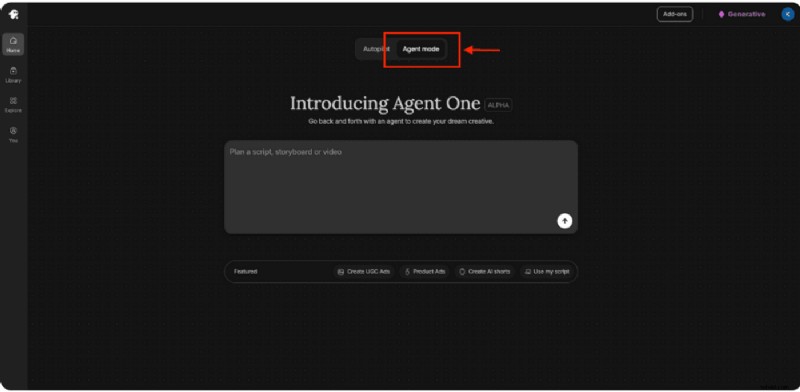
AgentOne requiere solo un paso:describir lo que necesita en un lenguaje sencillo y dejar que él elabore la sugerencia, idea y produzca variaciones, todo ello preservando su marca y el contexto de su escena.
Preguntas frecuentes
-
¿Qué es ChatGPT Images2.0?
GPT‑Image2 es el modelo de generación de imágenes más nuevo de OpenAI, lanzado el 21 de abril de 2026. Reemplaza el canal de imágenes GPT anterior y se convierte en el único modelo de imagen después de que DALL‑E2 y 3 se retiren el 12 de mayo de 2026.
-
¿Cómo uso ChatGPT Images2.0?
Puede generar imágenes directamente en ChatGPT o mediante InVideo. En InVideo, abra Agentes y modelos, seleccione GPT‑Image2, escriba un mensaje, establezca la resolución y las variaciones, y genere. El contexto de su marca se conserva a través de generaciones.
-
¿Cuál es la mayor mejora con respecto a GPT‑Image1.5?
La precisión de la representación del texto aumentó de ~90% a 95% a un 99%, lo que permite realizar carteles, anuncios, empaques, menús y maquetas de interfaz de usuario de una sola pasada que están listos para producción.
-
¿ChatGPT Images2.0 admite diferentes relaciones de aspecto?
Sí. Varía de 3:1 (ultra ancho) a 1:3 (vertical alto), incluidos 16:9 nativo y 9:16, más cuadrado. La salida estándar es 2K; 4K está disponible en la API beta.
-
¿Puede GPT‑Image2 generar texto en otros idiomas?
Sí. Representa chino, japonés, coreano, hindi, bengalí y árabe, abriendo mercados a los que los modelos anteriores no podían atender.
-
¿En qué aspectos ChatGPT Images2.0 aún se queda corto?
Tiene problemas con la física, la precisión estructural, los datos técnicos, los rostros en primer plano y el texto en superficies curvas o con ángulos pronunciados. La revisión humana sigue siendo recomendable para el trabajo de producción.
-
¿ChatGPT Images2.0 es mejor que Midjourney?
Depende de la tarea. GPT‑Image2 destaca por la precisión del texto, los recursos con gran diseño, la representación multilingüe y el seguimiento de instrucciones. La mitad del viaje puede conducir a un estilo visual puro.
-
¿GPT‑Image2 es una actualización importante?
Sí. Es el tercer modelo de imagen de OpenAI en trece meses, reconstruido desde cero con una nueva arquitectura. DALL‑E2 y 3 se están retirando, lo que convierte a GPT‑Image2 en el único modelo de imagen que seguirá adelante.
-
¿Cómo consigue GPT‑Image2 un texto preciso?
Los modelos anteriores aprendieron patrones visuales de texto; GPT‑Image2 es autorregresivo y genera tokens de texto como lenguaje, lo que garantiza la precisión semántica. Este cambio aumenta la precisión del texto del 90% al 95% al 99%.